
In this post, we’ll walk through a working RAG pipeline using climate science data from the IPCC to produce grounded, factual, and transparent responses with an LLM.
What Is RAG?
Retrieval-Augmented Generation (RAG) enhances LLMs by injecting context from a knowledge base during inference. Unlike traditional LLMs that may hallucinate or become outdated, RAG ensures:
- Easy to update—just replace the documents, no retraining needed
- Answers are grounded in your data (e.g., reports, PDFs)
- Reduces hallucinations by injecting factual context
A Simple Architecture: How It Works
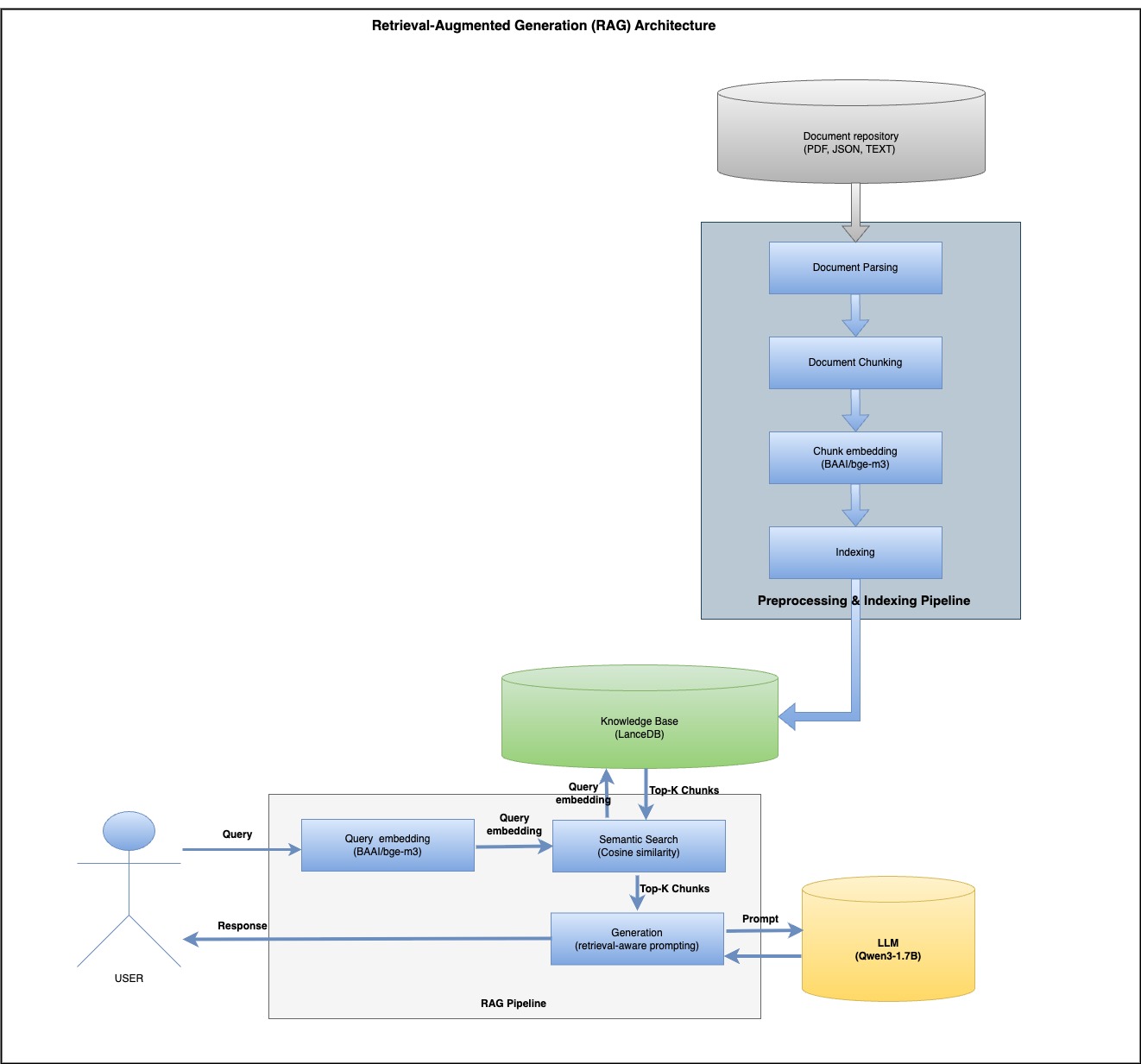
Step 1: Parsing & Chunking
We use docling and a hybrid tokenizer for clean document splitting:
# chunker.py
import os
from docling import chunking
from docling.document_converter import DocumentConverter
from docling_core.transforms.chunker.tokenizer.huggingface import HuggingFaceTokenizer
from transformers import AutoTokenizer
class Chunker:
def __init__(self, embedding_model: str, max_tokens: int = 1024):
tokenizer = HuggingFaceTokenizer(
tokenizer=AutoTokenizer.from_pretrained(embedding_model),
max_tokens=max_tokens,
)
self.__chunker = chunking.HybridChunker(tokenizer=tokenizer, merge_peers=True)
def chunk(self, source: str):
doc = DocumentConverter().convert(source=source).document
chunk_iter = self.__chunker.chunk(dl_doc=doc)
chunks = list(chunk_iter)
chunks_dicts = []
for chunk in chunks:
chunks_dicts.append(
{
"content": chunk.text,
"page_number": chunk.meta.doc_items[0].prov[0].page_no,
"pdf_name": os.path.basename(source),
}
)
return chunks_dicts
Step 2: Embedding with SentenceTransformer
# embedding.py
from typing import List
import torch
from sentence_transformers import SentenceTransformer
class CustomEmbeddings:
def __init__(
self,
model_name: str,
trust_remote_code: bool = True,
device: str = torch.device("cuda" if torch.cuda.is_available() else "cpu"),
normalize_embeddings: bool = True,
):
self.model_name = model_name
self.normalize_embeddings = normalize_embeddings
self.model = SentenceTransformer(
model_name,
trust_remote_code=trust_remote_code,
device=device,
)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
embeddings = self.model.encode(
texts,
normalize_embeddings=self.normalize_embeddings,
convert_to_tensor=False
)
return embeddings.tolist()
def embed_query(self, text: str) -> List[float]:
embedding = self.model.encode(
text,
normalize_embeddings=self.normalize_embeddings,
convert_to_tensor=False
)
return embedding.tolist()
@property
def embedding_dimension(self) -> int:
"""Get the dimension of the embeddings."""
return self.model.get_sentence_embedding_dimension()
Step 3: Indexing & Semantic Search with LanceDB
#lancedb.py
import lancedb
from lancedb.table import Table
from pandas import DataFrame
class LanceDB:
def __init__(self,
vector_storage_path: str = "./lancedb/vector_storage",
table_name: str = "knowledge_base"):
db = lancedb.connect(uri=vector_storage_path)
import pyarrow as pa
schema = pa.schema([
pa.field("content", pa.string()),
pa.field("page_number", pa.int32()),
pa.field("pdf_name", pa.string()),
pa.field("embeddings", pa.list_(pa.float32(), 1024)),
])
try:
db.create_table(table_name, schema=schema)
print(f"Table {table_name} created successfully.")
except Exception as e:
print(f"Table {table_name} already exists. {e}")
self.__table: Table = db.open_table(name=table_name)
def semantic_search(self, vector_query: list[float], n: int = 10, distance_threshold=0.50) -> DataFrame:
search_results = self.__table.search(vector_query, vector_column_name="embeddings").distance_type(
"cosine").limit(n).to_pandas()
print(f"search_results\n\n {search_results}")
return search_results.loc[search_results["_distance"] <= distance_threshold]
def get_count(self) -> int:
return self.__table.count_rows()
def save(self, df: DataFrame):
self.__table.add(df)
print(f"total records in lancedb : {self.__table.count_rows()}")
def create_index(self):
try:
self.__table.create_index(metric="cosine", vector_column_name="embeddings")
except Exception as e:
print(f"Seems index already exist {e}")
Step 4: Prompt Template
# prompt_template.py
class PromptTemplate:
@staticmethod
def build(context: str, question: str, max_token: int = 512) -> str:
prompt = f"""You are a Climate Science Assistant using IPCC research to explain climate change clearly and compassionately.
**Your Approach:**
- Use solid IPCC scientific evidence
- Explain concepts accessibly for all audiences
- Be honest about uncertainties while providing clear guidance
- Support responses with specific data and findings
- Remain helpful, accurate, and encouraging
- **Keep responses under {max_token} tokens**
**Available Scientific Context (IPCC 2023 Synthesis Report):**
{context}
**Question:**
{question}
**Your Response (max {max_token} tokens):**
"""
return prompt
Step 5: LLM Inference Using Qwen
# qwen_llm.py
from typing import List, Dict, Tuple
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenLLM:
def __init__(self, model_name: str = "Qwen/Qwen3-1.7B"):
self.model_name = model_name
self.tokenizer = None
self.model = None
self.device = None
self._load_model()
def _load_model(self) -> None:
print(f"Loading model: {self.model_name}")
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
self.model = AutoModelForCausalLM.from_pretrained(
self.model_name,
torch_dtype=torch.float16,
device_map="auto"
)
self.device = self.model.device
print(f"Model loaded successfully on device: {self.device}")
def _prepare_messages(self, prompt: str) -> List[Dict[str, str]]:
return [{"role": "user", "content": prompt}]
def _parse_thinking_content(self, output_ids: List[int]) -> Tuple[str, str]:
try:
# Find the index of </think> token (151668)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
# If </think> token not found, no thinking content
index = 0
thinking_content = self.tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
main_content = self.tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
return thinking_content, main_content
def invoke(self,
prompt: str,
max_new_tokens: int = 1024,
enable_thinking: bool = True,
return_thinking: bool = True,
**generation_kwargs) -> Dict[str, str]:
messages = self._prepare_messages(prompt)
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=enable_thinking
)
model_inputs = self.tokenizer([text], return_tensors="pt").to(self.device)
with torch.no_grad():
generated_ids = self.model.generate(
**model_inputs,
max_new_tokens=max_new_tokens,
**generation_kwargs
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
if enable_thinking and return_thinking:
thinking_content, main_content = self._parse_thinking_content(output_ids)
return {
"response": main_content,
"thinking": thinking_content
}
else:
content = self.tokenizer.decode(output_ids, skip_special_tokens=True).strip("\n")
return {
"response": content,
"thinking": ""
}
Step 6: Putting It All Together
# rag_main.py
import pandas as pd
from src.chunker.chunker import Chunker
from src.embedding.custom_embedding import CustomEmbeddings
from src.llm.qwen_llm import QwenLLM
from src.prompt.prompt_template import PromptTemplate
from src.storage.lancedb import LanceDB
pdf_data = "https://www.ipcc.ch/report/ar6/syr/downloads/report/IPCC_AR6_SYR_LongerReport.pdf"
EMBEDDING_MODEL = "BAAI/bge-m3"
LLM_MODEL = "Qwen/Qwen3-1.7B"
# initialize the embedding model
embeddings = CustomEmbeddings(model_name=EMBEDDING_MODEL)
# initialize the LLM
llm = QwenLLM(model_name=LLM_MODEL)
# initialize the Chunker
chunker = Chunker(embedding_model=EMBEDDING_MODEL)
# initialize the Vector DB
lancedb = LanceDB(table_name="rag_table")
# Run document Indexing
print("Start Chunking ....")
documents = chunker.chunk(pdf_data)
print("Chunking done....")
df = pd.DataFrame(documents, columns=["content", "page_number", "pdf_name"])
print("Start Embedding ....")
df["embeddings"] = df["content"].apply(embeddings.embed_query)
print("Embedding done....")
print(df)
print("Start saving ....")
lancedb.save(df)
# RAG
query = "How is climate change affecting biodiversity?"
vector_query = embeddings.embed_query(query)
result_df = lancedb.semantic_search(vector_query=vector_query, n=2)
context = "\n\n".join(result_df["content"].tolist())
formatted_prompt = PromptTemplate.build(context=context, question=query)
print("\nFormatted Prompt:" + "\n" + formatted_prompt)
final_response = llm.invoke(formatted_prompt, enable_thinking=True, return_thinking=True)
print("\nFinal RAG Response:")
print(final_response["response"])
Final Output Example
**Question:**
How is climate change affecting biodiversity?
**Your Response (max 512 tokens):**
Final RAG Response:
Climate change is profoundly impacting biodiversity through habitat loss, shifting species ranges, and ecosystem disruptions. For example, over 50% of coastal wetlands have been lost globally due to sea level rise, warming, and extreme events, threatening species like mangroves and sea turtles. Species are shifting poleward or uphill (very high confidence), but many cannot adapt fast enough to rising temperatures or extreme weather, leading to local extinctions (very high confidence). Heat extremes and mass mortality events (e.g., coral bleaching) have caused hundreds of species losses. Irreversible changes, such as glacier retreat altering freshwater systems, are accelerating. Ocean acidification and sea level rise also disrupt marine ecosystems. While some shifts occur, many ecosystems are approaching irreversible damage, underscoring the urgency of conservation and adaptive strategies to mitigate these impacts.
Why This Matters
- Trustworthy: Cites real IPCC data, not LLM guesswork
- Transparent: Users see the evidence used
- Customizable: Swap in any dataset or document
Here is the code repository
