
In this blog, I will describe, how to enable the S3 magic committer on the Spark cluster(Running on AWS Elastic Kubernetes Service).
Prerequisites:
- EKS Cluster on AWS
- Spark cluster setup on EKS
First, I will describe the need of s3 magic committer. I will take my use case as an example. Reading data from Postgres tables(meta, data ), joining them, and writing on S3. Here is the code:
Meta table:
val metaTable = s"(select * from analysis_meta where id >= 1220572171319017472 and id < 1620572171319017473) as meta"
val metaDf =
spark
.read
.format("jdbc")
.option("numPartitions" , "2000")
.option("lowerBound", "1220572171319017472")
.option("upperBound", "1620572171319017473")
.option("partitionColumn", "id")
.option("dbtable", metaTable)
.option("driver" , "org.postgresql.Driver")
.option("url", "jdbc:postgresql://AWS-RDS-URL.amazonaws.com/analysis_db?user=****&password=****")
.load()
Spark requires these parameters to partition the data of the table:
- numPartitions
- lowerBound
- upperBound
- partitionColumn
These parameters are mandatory otherwise spark will read all the data into a single partition.
Data table:
val textTable = s"(select id , text from analysis_data where id >= 1220572171319017472 and id < 1620572171319017473) as data"
val textDf =
spark
.read
.format("jdbc")
.option("numPartitions", "2000")
.option("lowerBound", "1220572171319017472")
.option("upperBound", "1620572171319017473")
.option("partitionColumn", "id")
.option("dbtable", textTable)
.option("driver", "org.postgresql.Driver")
.option("url", "jdbc:postgresql://AWS-RDS-URL.amazonaws.com/analysis_db?user=****&password=****")
.load()
Join the meta and data table then write on S3:
val df = metaDf.join(textDf, "id")
df
.write
.partitionBy("lang", "month") // partition by language and month
.mode(SaveMode.Append)
.parquet(s"s3a://bucket-name/analysis-data")
let’s run this job. Both tables have 80M rows(~ 400GB). It will take 1 hour to complete.
DAG:
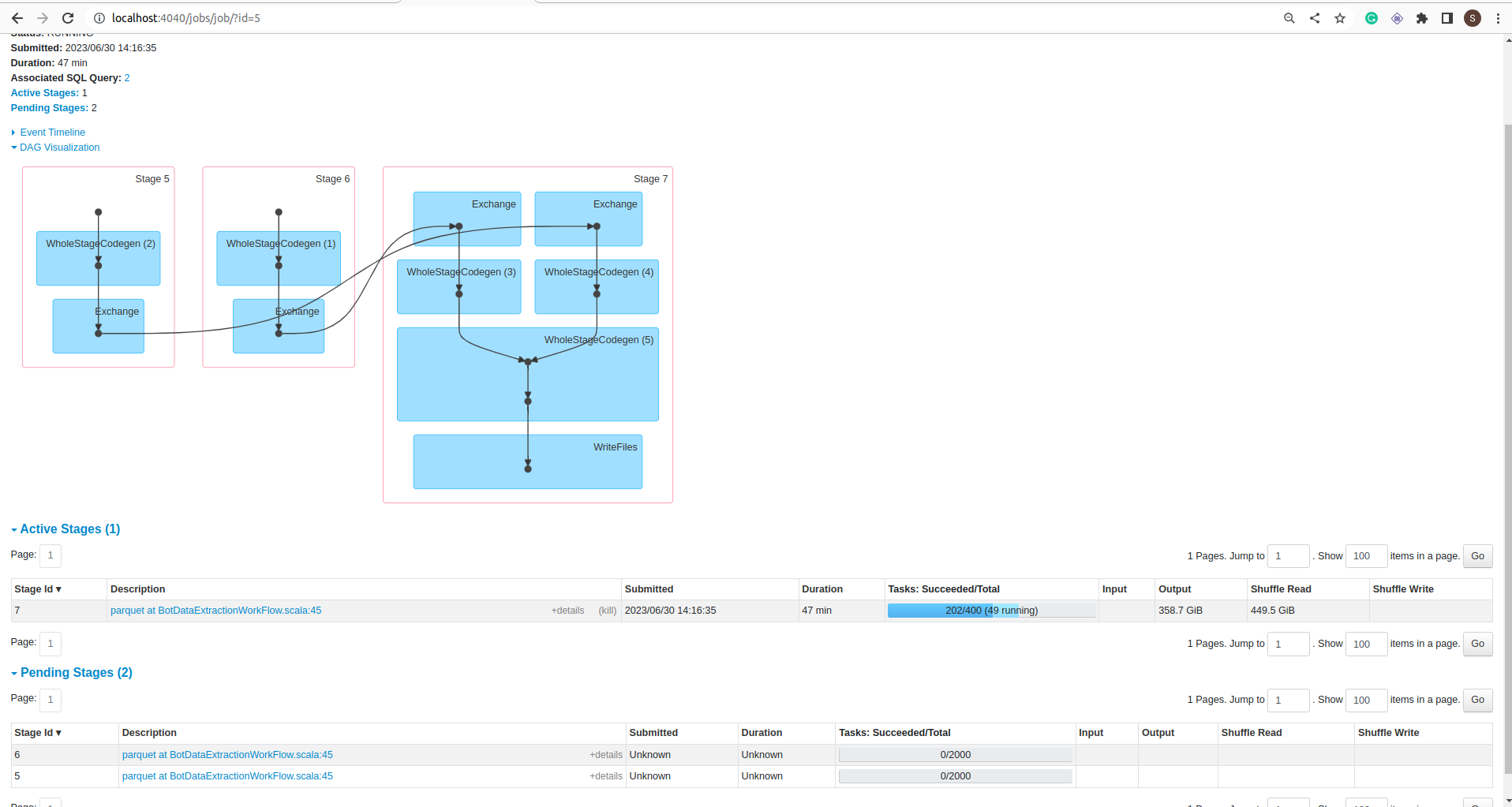
Stage:

Job:
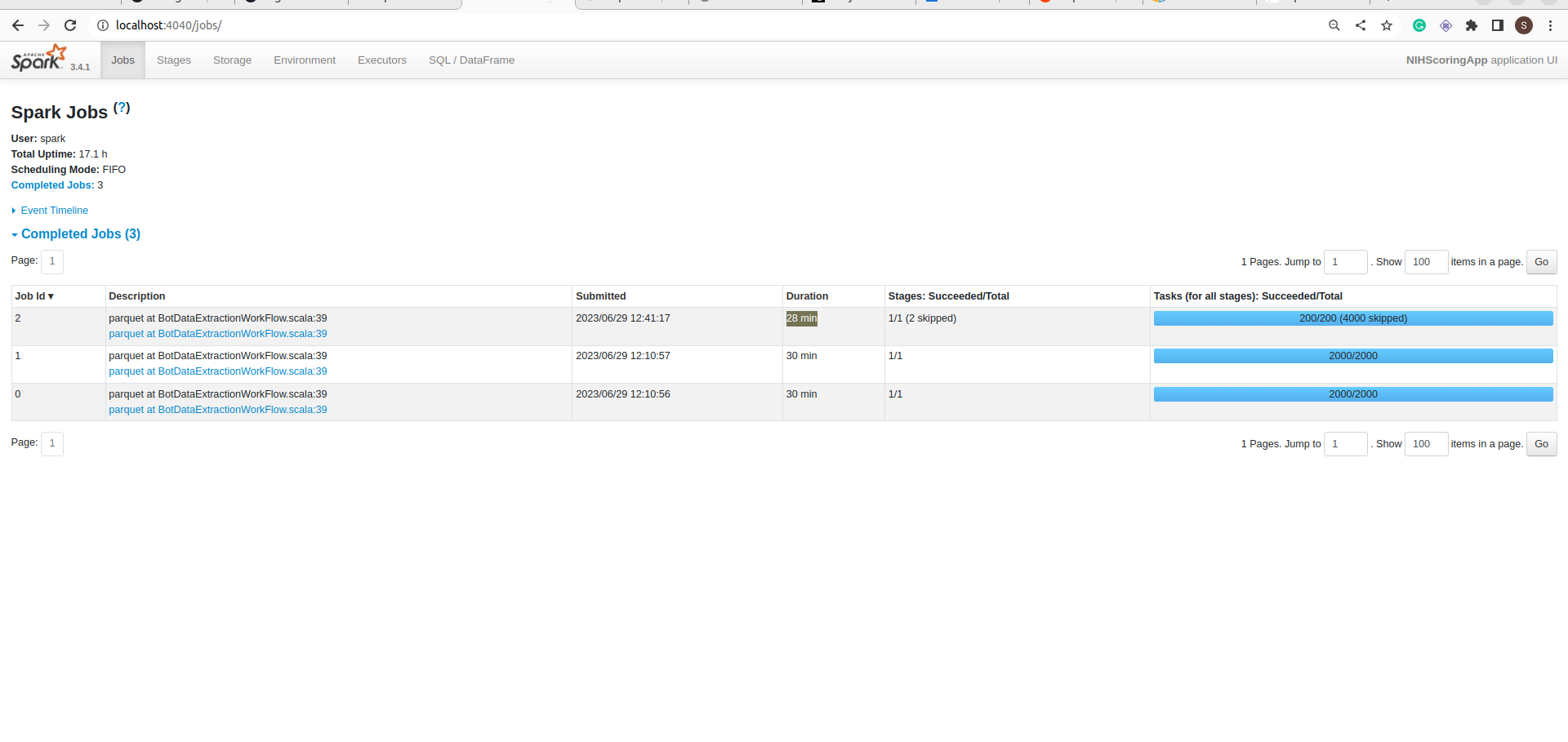
My Spark cluster size is 8 * m5.2xlarge nodes.
If you notice in the jobs details screenshot, the Job took 1 hour to complete but data is not committed into the folder. It is still in _temporary folder.
To commit all the data spark took more than 12 hours.
That was surprising but It is not a Spark problem. Spark is warning about that in the log:
11549:23/06/30 09:26:40 WARN AbstractS3ACommitterFactory: Using standard FileOutputCommitter to commit work. This is slow and potentially unsafe.
“Using standard FileOutputCommitter to commit work. This is slow and potentially unsafe.”
Let’s switch to the magic committer. It requires just a configuration change:
spark.hadoop.fs.s3a.bucket.all.committer.magic.enabled=true
and Spark Hadoop cloud dependency. I uploaded this jar on S3 and included it in the job submission.
I am running the spark cluster on EKS so here full job submission:
kubectl exec -ti --namespace spark spark-cluster-worker-0 -- spark-submit --master spark://spark-cluster-master-svc:7077 \
--conf 'spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem' \
--conf 'spark.hadoop.fs.s3a.bucket.all.committer.magic.enabled=true' \
--conf 'spark.hadoop.fs.s3a.connection.maximum=1000' \
--conf 'spark.driver.memory=8g' \
--conf 'spark.executor.memory=20g' \
--conf 'spark.executor.cores=6' \
--conf 'spark.sql.shuffle.partitions=400' \
--supervise \
--deploy-mode cluster \
--jars s3a://bucket-name/dependencies/spark-hadoop-cloud_2.12-3.3.2.jar \
--class com.techmonad.main.Postgres2S3App \
s3a://bucket-name/app/Postgres2S3App-30-06-2023_06_13.jar
The job took the same time but data is committed into a folder in 2 hours. Wow!!!!
here is the code.
References:

